## Get Started
Explore the API playground and try Exa API.
Use our SDKs to do your first Exa search.
Use our integrations to peform RAG with Exa.
Learn from our pre-built tutorials and live demos.
## Create a .env file Create a file called `.env` in the root of your project and add the following line. ```bash EXA_API_KEY=your api key without quotes ```
{" "} ## Make an API request Use our python or javascript SDKs, or call the API directly with cURL.
*** ## `search` Method Perform an Exa search given an input query and retrieve a list of relevant results as links.
### Input Example ```TypeScript const result = await exa.search( "hottest AI startups", { numResults: 2 } ); ```
### Input Parameters | Parameter | Type | Description | Default | | ------------------ | --------- | ---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------- | | query | string | The input query string. | Required | | numResults | number | Number of search results to return. | 10 | | includeDomains | string\[] | List of domains to include in the search. | undefined | | excludeDomains | string\[] | List of domains to exclude in the search. | undefined | | startCrawlDate | string | Results will only include links **crawled** after this date. | undefined | | endCrawlDate | string | Results will only include links **crawled** before this date. | undefined | | startPublishedDate | string | Results will only include links with a **published** date after this date. | undefined | | endPublishedDate | string | Results will only include links with a **published** date before this date. | undefined | | type | string | The type of search, "keyword" or "neural". | "auto" | | category | string | data category to focus on when searching, with higher comprehensivity and data cleanliness. Available categories: "company", "research paper", "news", "linkedin profile", "github", "tweet", "movie", "song", "personal site", "pdf", "financial report". | undefined |
### Returns Example ```JSON { "autopromptString": "Here is a link to one of the hottest AI startups:", "results": [ { "score": 0.17025552690029144, "title": "Adept: Useful General Intelligence", "id": "https://www.adept.ai/", "url": "https://www.adept.ai/", "publishedDate": "2000-01-01", "author": null }, { "score": 0.1700288951396942, "title": "Home | Tenyx, Inc.", "id": "https://www.tenyx.com/", "url": "https://www.tenyx.com/", "publishedDate": "2019-09-10", "author": null } ] } ```
### Return Parameters ### `SearchResponse` | Field | Type | Description | | ------- | --------- | ---------------------- | | results | Result\[] | List of Result objects |
### `Result` Object | Field | Type | Description | | -------------- | -------------- | --------------------------------------------- | | url | string | URL of the search result | | id | string | Temporary ID for the document | | title | string \| null | Title of the search result | | score? | number | Similarity score between query/url and result | | publishedDate? | string | Estimated creation date | | author? | string | Author of the content, if available |
## `searchAndContents` Method Perform an Exa search given an input query and retrieve a list of relevant results as links, optionally including the full text and/or highlights of the content.
### Input Example ```TypeScript TypeScript // Search with full text content const resultWithText = await exa.searchAndContents( "AI in healthcare", { text: true, numResults: 2 } ); // Search with highlights const resultWithHighlights = await exa.searchAndContents( "AI in healthcare", { highlights: true, numResults: 2 } ); // Search with both text and highlights const resultWithTextAndHighlights = await exa.searchAndContents( "AI in healthcare", { text: true, highlights: true, numResults: 2 } ); // Search with structured summary schema const companySchema = { "$schema": "http://json-schema.org/draft-07/schema#", "title": "Company Information", "type": "object", "properties": { "name": { "type": "string", "description": "The name of the company" }, "industry": { "type": "string", "description": "The industry the company operates in" }, "foundedYear": { "type": "number", "description": "The year the company was founded" }, "keyProducts": { "type": "array", "items": { "type": "string" }, "description": "List of key products or services offered by the company" }, "competitors": { "type": "array", "items": { "type": "string" }, "description": "List of main competitors" } }, "required": ["name", "industry"] }; const resultWithStructuredSummary = await exa.searchAndContents( "OpenAI company information", { summary: { schema: companySchema }, category: "company", numResults: 3 } ); // Parse the structured summary (returned as a JSON string) const firstResult = resultWithStructuredSummary.results[0]; if (firstResult.summary) { const structuredData = JSON.parse(firstResult.summary); console.log(structuredData.name); // e.g. "OpenAI" console.log(structuredData.industry); // e.g. "Artificial Intelligence" console.log(structuredData.keyProducts); // e.g. ["GPT-4", "DALL-E", "ChatGPT"] } ```
### Input Parameters | Parameter | Type | Description | Default | | ------------------ | -------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- | --------- | | query | string | The input query string. | Required | | text | boolean \| \{ maxCharacters?: number, includeHtmlTags?: boolean } | If provided, includes the full text of the content in the results. | undefined | | highlights | boolean \| \{ query?: string, numSentences?: number, highlightsPerUrl?: number } | If provided, includes highlights of the content in the results. | undefined | | numResults | number | Number of search results to return. | 10 | | includeDomains | string\[] | List of domains to include in the search. | undefined | | excludeDomains | string\[] | List of domains to exclude in the search. | undefined | | startCrawlDate | string | Results will only include links **crawled** after this date. | undefined | | endCrawlDate | string | Results will only include links **crawled** before this date. | undefined | | startPublishedDate | string | Results will only include links with a **published** date after this date. | undefined | | endPublishedDate | string | Results will only include links with a **published** date before this date. | undefined | | type | string | The type of search, "keyword" or "neural". | "auto" | | category | string | A data category to focus on when searching, with higher comprehensivity and data cleanliness. Available categories: "company", "research paper", "news", "linkedin profile", "github", "tweet", "movie", "song", "personal site", "pdf" and "financial report". | undefined |
### Returns Example ```JSON JSON { "results": [ { "score": 0.20826785266399384, "title": "2023 AI Trends in Health Care", "id": "https://aibusiness.com/verticals/2023-ai-trends-in-health-care-", "url": "https://aibusiness.com/verticals/2023-ai-trends-in-health-care-", "publishedDate": "2022-12-29", "author": "Wylie Wong", "text": "While the health care industry was initially slow to [... TRUNCATED FOR BREVITY ...]", "highlights": [ "But to do so, many health care institutions would like to share data, so they can build a more comprehensive dataset to use to train an AI model. Traditionally, they would have to move the data to one central repository. However, with federated or swarm learning, the data does not have to move. Instead, the AI model goes to each individual health care facility and trains on the data, he said. This way, health care providers can maintain security and governance over their data." ], "highlightScores": [ 0.5566554069519043 ] }, { "score": 0.20796334743499756, "title": "AI in healthcare: Innovative use cases and applications", "id": "https://www.leewayhertz.com/ai-use-cases-in-healthcare", "url": "https://www.leewayhertz.com/ai-use-cases-in-healthcare", "publishedDate": "2023-02-13", "author": "Akash Takyar", "text": "The integration of AI in healthcare is not [... TRUNCATED FOR BREVITY ...]", "highlights": [ "The ability of AI to analyze large amounts of medical data and identify patterns has led to more accurate and timely diagnoses. This has been especially helpful in identifying complex medical conditions, which may be difficult to detect using traditional methods. Here are some examples of successful implementation of AI in healthcare. IBM Watson Health: IBM Watson Health is an AI-powered system used in healthcare to improve patient care and outcomes. The system uses natural language processing and machine learning to analyze large amounts of data and provide personalized treatment plans for patients." ], "highlightScores": [ 0.6563674807548523 ] } ] } ```
### Return Parameters
### `SearchResponse` | Field | Type | Description | | ------- | ------------------- | ---------------------------- | | results | SearchResult\
### `SearchResult` Extends the `Result` object from the `search` method with additional fields based on `T`: | Field | Type | Description | | ---------------- | --------- | ---------------------------------------------- | | text? | string | Text of the search result page (if requested) | | highlights? | string\[] | Highlights of the search result (if requested) | | highlightScores? | number\[] | Scores of the highlights (if requested) | Note: The actual fields present in the `SearchResult
## `findSimilar` Method Find a list of similar results based on a webpage's URL.
### Input Example ```TypeScript const similarResults = await exa.findSimilar( "https://www.example.com", { numResults: 2, excludeSourceDomain: true } ); ```
### Input Parameters | Parameter | Type | Description | Default | | ------------------- | --------- | --------------------------------------------------------------------------------------------- | --------- | | url | string | The URL of the webpage to find similar results for. | Required | | numResults | number | Number of similar results to return. | undefined | | includeDomains | string\[] | List of domains to include in the search. | undefined | | excludeDomains | string\[] | List of domains to exclude from the search. | undefined | | startCrawlDate | string | Results will only include links **crawled** after this date. | undefined | | endCrawlDate | string | Results will only include links **crawled** before this date. | undefined | | startPublishedDate | string | Results will only include links with a **published** date after this date. | undefined | | endPublishedDate | string | Results will only include links with a **published** date before this date. | undefined | | excludeSourceDomain | boolean | If true, excludes results from the same domain as the input URL. | undefined | | category | string | A data category to focus on when searching, with higher comprehensivity and data cleanliness. | undefined |
### Returns Example ```JSON JSON { "results": [ { "score": 0.8777582049369812, "title": "Play New Free Online Games Every Day", "id": "https://www.minigames.com/new-games", "url": "https://www.minigames.com/new-games", "publishedDate": "2000-01-01", "author": null }, { "score": 0.87653648853302, "title": "Play The best Online Games", "id": "https://www.minigames.com/", "url": "https://www.minigames.com/", "publishedDate": "2000-01-01", "author": null } ] } ```
### Return Parameters
### `SearchResponse` | Field | Type | Description | | ------- | --------- | ---------------------- | | results | Result\[] | List of Result objects |
### `Result` Object | Field | Type | Description | | -------------- | -------------- | --------------------------------------------- | | url | string | URL of the search result | | id | string | Temporary ID for the document | | title | string \| null | Title of the search result | | score? | number | Similarity score between query/url and result | | publishedDate? | string | Estimated creation date | | author? | string | Author of the content, if available |
*** ## `findSimilarAndContents` Method Find a list of similar results based on a webpage's URL, optionally including the text content or highlights of each result.
### Input Example ```TypeScript TypeScript // Find similar with full text content const similarWithText = await exa.findSimilarAndContents( "https://www.example.com/article", { text: true, numResults: 2 } ); // Find similar with highlights const similarWithHighlights = await exa.findSimilarAndContents( "https://www.example.com/article", { highlights: true, numResults: 2 } ); // Find similar with both text and highlights const similarWithTextAndHighlights = await exa.findSimilarAndContents( "https://www.example.com/article", { text: true, highlights: true, numResults: 2, excludeSourceDomain: true } ); ```
### Input Parameters | Parameter | Type | Description | Default | | ------------------- | -------------------------------------------------------------------------------- | --------------------------------------------------------------------------------------------- | --------- | | url | string | The URL of the webpage to find similar results for. | Required | | text | boolean \| \{ maxCharacters?: number, includeHtmlTags?: boolean } | If provided, includes the full text of the content in the results. | undefined | | highlights | boolean \| \{ query?: string, numSentences?: number, highlightsPerUrl?: number } | If provided, includes highlights of the content in the results. | undefined | | numResults | number | Number of similar results to return. | undefined | | includeDomains | string\[] | List of domains to include in the search. | undefined | | excludeDomains | string\[] | List of domains to exclude from the search. | undefined | | startCrawlDate | string | Results will only include links **crawled** after this date. | undefined | | endCrawlDate | string | Results will only include links **crawled** before this date. | undefined | | startPublishedDate | string | Results will only include links with a **published** date after this date. | undefined | | endPublishedDate | string | Results will only include links with a **published** date before this date. | undefined | | excludeSourceDomain | boolean | If true, excludes results from the same domain as the input URL. | undefined | | category | string | A data category to focus on when searching, with higher comprehensivity and data cleanliness. | undefined |
### Returns Example ```JSON JSON { "results": [ { "score": 0.8777582049369812, "title": "Similar Article: AI and Machine Learning", "id": "https://www.similarsite.com/ai-ml-article", "url": "https://www.similarsite.com/ai-ml-article", "publishedDate": "2023-05-15", "author": "Jane Doe", "text": "Artificial Intelligence (AI) and Machine Learning (ML) are revolutionizing various industries. [... TRUNCATED FOR BREVITY ...]", "highlights": [ "AI and ML are transforming how businesses operate, enabling more efficient processes and data-driven decision making.", "The future of AI looks promising, with potential applications in healthcare, finance, and autonomous vehicles." ], "highlightScores": [ 0.95, 0.89 ] }, { "score": 0.87653648853302, "title": "The Impact of AI on Modern Technology", "id": "https://www.techblog.com/ai-impact", "url": "https://www.techblog.com/ai-impact", "publishedDate": "2023-06-01", "author": "John Smith", "text": "In recent years, artificial intelligence has made significant strides in various technological domains. [... TRUNCATED FOR BREVITY ...]", "highlights": [ "AI is not just a buzzword; it's a transformative technology that's reshaping industries and creating new opportunities.", "As AI continues to evolve, ethical considerations and responsible development become increasingly important." ], "highlightScores": [ 0.92, 0.88 ] } ] } ```
### Return Parameters
### `SearchResponse` | Field | Type | Description | | ------- | ------------------- | ---------------------------- | | results | SearchResult\
*** ## `getContents` Method Retrieves contents of documents based on a list of document IDs.
### Input Example ```TypeScript TypeScript // Get contents for a single ID const singleContent = await exa.getContents("https://www.example.com/article"); // Get contents for multiple IDs const multipleContents = await exa.getContents([ "https://www.example.com/article1", "https://www.example.com/article2" ]); // Get contents with specific options const contentsWithOptions = await exa.getContents( ["https://www.example.com/article1", "https://www.example.com/article2"], { text: { maxCharacters: 1000 }, highlights: { query: "AI", numSentences: 2 } } ); ```
### Input Parameters | Parameter | Type | Description | Default | | ---------- | -------------------------------------------------------------------------------- | ------------------------------------------------------------------ | --------- | | ids | string \| string\[] \| SearchResult\[]\` | A single ID, an array of IDs, or an array of SearchResults. | Required | | text | boolean \| \{ maxCharacters?: number, includeHtmlTags?: boolean } | If provided, includes the full text of the content in the results. | undefined | | highlights | boolean \| \{ query?: string, numSentences?: number, highlightsPerUrl?: number } | If provided, includes highlights of the content in the results. | undefined |
### Returns Example ```JSON JSON { "results": [ { "id": "https://www.example.com/article1", "url": "https://www.example.com/article1", "title": "The Future of Artificial Intelligence", "publishedDate": "2023-06-15", "author": "Jane Doe", "text": "Artificial Intelligence (AI) has made significant strides in recent years. [... TRUNCATED FOR BREVITY ...]", "highlights": [ "AI is revolutionizing industries from healthcare to finance, enabling more efficient processes and data-driven decision making.", "As AI continues to evolve, ethical considerations and responsible development become increasingly important." ], "highlightScores": [ 0.95, 0.92 ] }, { "id": "https://www.example.com/article2", "url": "https://www.example.com/article2", "title": "Machine Learning Applications in Business", "publishedDate": "2023-06-20", "author": "John Smith", "text": "Machine Learning (ML) is transforming how businesses operate and make decisions. [... TRUNCATED FOR BREVITY ...]", "highlights": [ "Machine Learning algorithms can analyze vast amounts of data to identify patterns and make predictions.", "Businesses are leveraging ML for customer segmentation, demand forecasting, and fraud detection." ], "highlightScores": [ 0.93, 0.90 ] } ] } ```
### Return Parameters
### `SearchResponse` | Field | Type | Description | | ------- | ------------------- | ---------------------------- | | results | SearchResult\
### `SearchResult` The fields in the `SearchResult
*** ## `answer` Method Generate an answer to a query using Exa's search and LLM capabilities. This returns an AnswerResponse object with the answer text and citations used. You may optionally retrieve the full text of each source by setting `text: true`.
### Input Example ```TypeScript TypeScript // Basic usage const answerResponse = await exa.answer("What is the capital of France?"); console.log(answerResponse); // If you want the full text of each citation in the result const answerWithText = await exa.answer("What is the capital of France?", { text: true }); console.log(answerWithText); ```
### Input Parameters | Parameter | Type | Description | Default | | --------- | ----------------- | ------------------------------------------------------------------ | -------- | | query | string | The question or query to answer. | Required | | options | \{text?: boolean} | If text is true, each source in the result includes its full text. | {} |
### Returns Example ```JSON JSON { "answer": "The capital of France is Paris.", "citations": [ { "id": "https://www.example.com/france", "url": "https://www.example.com/france", "title": "France - Wikipedia", "publishedDate": "2023-01-01", "author": null, "text": "France, officially the French Republic, is a country in... [truncated for brevity]" } ], "requestId": "abc123" } ```
### Return Parameters #### `AnswerResponse` ```TypeScript TypeScript interface AnswerResponse { answer: string; citations: SearchResult<{}>[]; requestId?: string; } ``` | Field | Type | Description | | ---------- | ---------------------- | ----------------------------------------- | | answer | string | The generated answer text | | citations | SearchResult\<\{ }>\[] | The citations used to generate the answer | | requestId? | string | Optional request ID for reference | Each citation is a `SearchResult<{}>` — a basic result object that can include text if options.text was set to true.
*** ## `streamAnswer` Method Generate a streaming answer to a query with Exa's LLM capabilities. This returns an async generator yielding chunks of text and/or citations as they become available.
### Input Example ```TypeScript TypeScript for await (const chunk of exa.streamAnswer("Explain quantum entanglement in simple terms.", { text: true })) { if (chunk.content) { process.stdout.write(chunk.content); // partial text } if (chunk.citations) { console.log("\nCitations:"); console.log(chunk.citations); } } ```
### Input Parameters | Parameter | Type | Description | Default | | --------- | ------------------- | ------------------------------------------------------------ | -------- | | query | string | The question to answer. | Required | | options | \{ text?: boolean } | If text is true, each citation chunk includes its full text. | {} |
### Return Type An async generator of objects with the type: ```TypeScript TypeScript interface AnswerStreamChunk { content?: string; citations?: Array<{ id: string; url: string; title?: string; publishedDate?: string; author?: string; text?: string; }>; } ``` * `content` is the partial text content of the answer so far (streamed in chunks). * `citations` is an array of citation objects that appear at this chunk in the response. You can end iteration by using a break or by letting the loop finish naturally.
*** ## `research.createTask` Method Create an asynchronous research task that performs multi-step web research and returns structured JSON results with citations.
### Input Example ```TypeScript TypeScript import Exa, { ResearchModel } from "exa-js"; const exa = new Exa(process.env.EXA_API_KEY); // Simple research task const instructions = "What is the latest valuation of SpaceX?"; const schema = { type: "object", properties: { valuation: { type: "string" }, date: { type: "string" }, source: { type: "string" } } }; const task = await exa.research.createTask({ instructions: instructions, output: { schema: schema } }); // Or even simpler - let the model infer the schema const simpleTask = await exa.research.createTask({ instructions: "What are the main benefits of meditation?", output: { inferSchema: true } }); console.log(`Task created with ID: ${task.id}`); ```
### Input Parameters | Parameter | Type | Description | Default | | ------------ | ------------------------------------------- | ------------------------------------------------------------------------------------------------- | ------------- | | instructions | string | Natural language instructions describing what the research task should accomplish. | Required | | model | ResearchModel | The research model to use. Options: ResearchModel.exa\_research, ResearchModel.exa\_research\_pro | exa\_research | | output | \{ schema?: object, inferSchema?: boolean } | Output configuration with optional JSON schema or automatic schema inference. | undefined |
### Returns Example ```JSON JSON { "id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890" } ```
### Return Type ```TypeScript TypeScript interface CreateTaskResponse { id: string; } ``` | Field | Type | Description | | ----- | ------ | ---------------------------------- | | id | string | The unique identifier for the task |
## `research.getTask` Method Get the current status and results of a research task by its ID.
### Input Example ```TypeScript TypeScript // Get a research task by ID const taskId = "your-task-id-here"; const task = await exa.research.getTask(taskId); console.log(`Task status: ${task.status}`); if (task.status === "completed") { console.log(`Results: ${JSON.stringify(task.data)}`); console.log(`Citations: ${JSON.stringify(task.citations)}`); } ```
### Input Parameters | Parameter | Type | Description | Default | | --------- | ------ | --------------------------------- | -------- | | id | string | The unique identifier of the task | Required |
### Returns Example ```JSON JSON { "id": "a1b2c3d4-e5f6-7890-abcd-ef1234567890", "status": "completed", "instructions": "What is the latest valuation of SpaceX?", "schema": { "type": "object", "properties": { "valuation": {"type": "string"}, "date": {"type": "string"}, "source": {"type": "string"} } }, "data": { "valuation": "$350 billion", "date": "December 2024", "source": "Financial Times" }, "citations": { "valuation": [ { "id": "https://www.ft.com/content/...", "url": "https://www.ft.com/content/...", "title": "SpaceX valued at $350bn in employee share sale", "snippet": "SpaceX has been valued at $350bn..." } ] } } ```
### Return Type ```TypeScript TypeScript interface ResearchTask { id: string; status: "running" | "completed" | "failed"; instructions: string; schema?: object; data?: object; citations?: Record
## `research.pollTask` Method Poll a research task until it completes or fails, returning the final result.
### Input Example ```TypeScript TypeScript // Create and poll a task until completion const task = await exa.research.createTask({ instructions: "Get information about Paris, France", output: { schema: { type: "object", properties: { name: { type: "string" }, population: { type: "string" }, founded_date: { type: "string" } } } } }); // Poll until completion const result = await exa.research.pollTask(task.id); console.log(`Research complete: ${JSON.stringify(result.data)}`); ```
### Input Parameters | Parameter | Type | Description | Default | | --------- | ------ | --------------------------------- | -------- | | id | string | The unique identifier of the task | Required | Note: The pollTask method automatically polls every 1 second with a timeout of 10 minutes.
### Returns Returns a `ResearchTask` object with the completed task data (same structure as `getTask`).
## `research.listTasks` Method List all research tasks with optional pagination.
### Input Example ```TypeScript TypeScript // List all research tasks const response = await exa.research.listTasks(); console.log(`Found ${response.data.length} tasks`); // List with pagination const paginatedResponse = await exa.research.listTasks({ limit: 10 }); if (paginatedResponse.hasMore) { const nextPage = await exa.research.listTasks({ cursor: paginatedResponse.nextCursor }); } ```
### Input Parameters | Parameter | Type | Description | Default | | --------- | ------ | --------------------------------------- | --------- | | cursor | string | Pagination cursor from previous request | undefined | | limit | number | Number of results to return (1-200) | 25 |
### Returns Example ```JSON JSON { "data": [ { "id": "task-1", "status": "completed", "instructions": "Research SpaceX valuation", ... }, { "id": "task-2", "status": "running", "instructions": "Compare GPU specifications", ... } ], "hasMore": true, "nextCursor": "eyJjcmVhdGVkQXQiOiIyMDI0LTAxLTE1VDE4OjMwOjAwWiIsImlkIjoidGFzay0yIn0=" } ```
### Return Type ```TypeScript TypeScript interface ListTasksResponse { data: ResearchTask[]; hasMore: boolean; nextCursor?: string; } ``` | Field | Type | Description | | ---------- | ----------------- | --------------------------------------------- | | data | ResearchTask\[] | List of research task objects | | hasMore | boolean | Whether there are more results to paginate | | nextCursor | string (optional) | Cursor for the next page (if hasMore is true) | # Get an Event Source: https://docs.exa.ai/websets/api/events/get-an-event get /v0/events/{id} Get a single Event by id. You can subscribe to Events by creating a Webhook. # List all Events Source: https://docs.exa.ai/websets/api/events/list-all-events get /v0/events List all events that have occurred in the system. You can paginate through the results using the `cursor` parameter. # Event Types Source: https://docs.exa.ai/websets/api/events/types Learn about the events that occur within the Webset API The Websets API uses events to notify you about changes in your Websets. You can monitor these events through our [events endpoint](/websets/api/events/list-all-events) or by setting up [webhooks](/websets/api/webhooks/create-a-webhook). ## Webset * `webset.created` - Emitted when a new Webset is created. * `webset.deleted` - Emitted when a Webset is deleted. * `webset.paused` - Emitted when a Webset's operations are paused. * `webset.idle` - Emitted when a Webset has no running operations. ## Search * `webset.search.created` - Emitted when a new search is initiated. * `webset.search.updated` - Emitted when search progress is updated. * `webset.search.completed` - Emitted when a search finishes finding all items. * `webset.search.canceled` - Emitted when a search is manually canceled. ## Item * `webset.item.created` - Emitted when a new item has been added to the Webset. * `webset.item.enriched` - Emitted when an item's enrichment is completed. ## Import * `import.created` - Emitted when a new import is initiated. * `import.completed` - Emitted when an import has been completed. Each event includes: * A unique `id` * The event `type` * A `data` object containing the full resource that triggered the event * A `createdAt` timestamp You can use these events to: * Track the progress of searches and enrichments * Build real-time dashboards * Trigger workflows when new items are found * Monitor the status of your exports # Get started Source: https://docs.exa.ai/websets/api/get-started Create your first Webset ## Create and setup your API key 1. Go to the [Exa Dashboard](https://dashboard.exa.ai) 2. Click on "API Keys" in the left sidebar 3. Click "Create API Key" 4. Give your key a name and click "Create" 5. Copy your API key and store it securely - you won't be able to see it again!
## Create a .env file Create a file called `.env` in the root of your project and add the following line. ```bash EXA_API_KEY=your api key without quotes ```
## Make an API request Use our Python or JavaScript SDKs, or call the API directly with cURL.
***
## Running Additional Searches You can [create additional searches](/websets/api/create-a-search) on the same Webset at any time. Each new search: * Follows the same event flow as the initial search * Can run in parallel with other enrichment operations (not other searches for now) * Maintains its own progress tracking * Contributes to the overall Webset state ### Control Operations Manage your searches with: * [Cancel specific searches](/websets/api/cancel-a-running-search) * [Cancel all operations](/websets/api/cancel-a-running-webset)
***
## Up-to-date Websets using Monitors **[Monitors](/websets/api/monitors/create-a-monitor)** allow you to automatically keep your Websets updated with fresh data on a schedule, creating a continuous flow of updates without manual intervention. ### Behavior * **Search behavior**: Automatically run new searches to find fresh content matching your criteria. New items are added to your Webset with automatic deduplication. * **Refresh behavior**: Update existing items by refreshing their content from source URLs or re-running specific enrichments to capture data changes. ### Scheduling Set your update frequency with: * **Cron Expression**: A valid Unix cron expression with 5 fields that triggers at most once per day * **Timezone**: Any IANA timezone (defaults to `Etc/UTC`) ### Example: Weekly Monitor for Series A Funded Companies ```json { "websetId": "ws_abc123", "cadence": { "cron": "0 9 * * 1", "timezone": "America/New_York" }, "behavior": { "type": "search", "config": { "parameters": { "query": "AI startups that raised Series A funding in the last week", "count": 10, "criteria": [ { "description": "Company is an AI startup" }, { "description": "Company has raised Series A funding in the last week" } ], "entity": { "type": "company" }, "behavior": "append" } } } } ``` # Create an Import Source: https://docs.exa.ai/websets/api/imports/create-an-import post /v0/imports Creates a new import to upload your data into Websets. Imports can be used to: - **Enrich**: Enhance your data with additional information using our AI-powered enrichment engine - **Search**: Query your data using Websets' agentic search with natural language filters - **Exclude**: Prevent duplicate or already known results from appearing in your searches Once the import is created, you can upload your data to the returned `uploadUrl` until `uploadValidUntil` (by default 1 hour). # Delete Import Source: https://docs.exa.ai/websets/api/imports/delete-import delete /v0/imports/{id} Deletes a import. # Get Import Source: https://docs.exa.ai/websets/api/imports/get-import get /v0/imports/{id} Gets a specific import. # List Imports Source: https://docs.exa.ai/websets/api/imports/list-imports get /v0/imports Lists all imports for the Webset. # Update Import Source: https://docs.exa.ai/websets/api/imports/update-import patch /v0/imports/{id} Updates a import configuration. # Create a Monitor Source: https://docs.exa.ai/websets/api/monitors/create-a-monitor post /v0/monitors Creates a new `Monitor` to continuously keep your Websets updated with fresh data. Monitors automatically run on your defined schedule to ensure your Websets stay current without manual intervention: - **Find new content**: Execute `search` operations to discover fresh items matching your criteria - **Update existing content**: Run `refresh` operations to update items contents and enrichments - **Automated scheduling**: Configure `cron` expressions and `timezone` for precise scheduling control # Delete Monitor Source: https://docs.exa.ai/websets/api/monitors/delete-monitor delete /v0/monitors/{id} Deletes a monitor. # Get Monitor Source: https://docs.exa.ai/websets/api/monitors/get-monitor get /v0/monitors/{id} Gets a specific monitor. # List Monitors Source: https://docs.exa.ai/websets/api/monitors/list-monitors get /v0/monitors Lists all monitors for the Webset. # Get Monitor Run Source: https://docs.exa.ai/websets/api/monitors/runs/get-monitor-run get /v0/monitors/{monitor}/runs/{id} Gets a specific monitor run. # List Monitor Runs Source: https://docs.exa.ai/websets/api/monitors/runs/list-monitor-runs get /v0/monitors/{monitor}/runs Lists all runs for the Monitor. # Update Monitor Source: https://docs.exa.ai/websets/api/monitors/update-monitor patch /v0/monitors/{id} Updates a monitor configuration. # Overview Source: https://docs.exa.ai/websets/api/overview The Websets API helps you find, verify, and process web data at scale to build your unique collection of web content. The Websets API helps you create your own unique slice of the web by organizing content in containers (`Webset`). These containers store structured results (`WebsetItem`) which are discovered by search agents (`WebsetSearch`) that find web pages matching your specific criteria. Once these items are added to your Webset, they can be further processed with enrichment agents to extract additional data. Whether you're looking for companies, people, or research papers, each result becomes a structured Item with source content, verification status, and type-specific fields. These Items can be further enriched with enrichments. ## Key Features At its core, the API is: * **Asynchronous**: It's an async-first API. Searches (`Webset Search`) can take from seconds to minutes, depending on the complexity. * **Structured**: Every result (`Webset Item`) includes structured properties, webpage content, and verification against your criteria, with reasoning and references explaining why it matches. * **Event-Driven**: Events are published and delivered through webhooks to notify when items are found and when enrichments complete, allowing you to process data as it arrives. ## Core Objects
 * **Webset**: Container that organizes your unique collection of web content and its related searches
* **Search**: An agent that searches and crawls the web to find precise entities matching your criteria, adding them to your Webset as structured WebsetItems
* **Item**: A structured result with source content, verification status, and type-specific fields (company, person, research paper, etc.)
* **Enrichment**: An agent that searches the web to enhance existing WebsetItems with additional structured data
## Next Steps
* Follow our [quickstart guide](/websets/api/get-started)
* Learn more about [how it works](/websets/api/how-it-works)
* Browse the [API reference](/websets/api/websets/create-a-webset)
# List webhook attempts
Source: https://docs.exa.ai/websets/api/webhooks/attempts/list-webhook-attempts
get /v0/webhooks/{id}/attempts
List all attempts made by a Webhook ordered in descending order.
# Create a Webhook
Source: https://docs.exa.ai/websets/api/webhooks/create-a-webhook
post /v0/webhooks
# Delete a Webhook
Source: https://docs.exa.ai/websets/api/webhooks/delete-a-webhook
delete /v0/webhooks/{id}
# Get a Webhook
Source: https://docs.exa.ai/websets/api/webhooks/get-a-webhook
get /v0/webhooks/{id}
# List webhooks
Source: https://docs.exa.ai/websets/api/webhooks/list-webhooks
get /v0/webhooks
# Update a Webhook
Source: https://docs.exa.ai/websets/api/webhooks/update-a-webhook
patch /v0/webhooks/{id}
# Verifying Signatures
Source: https://docs.exa.ai/websets/api/webhooks/verifying-signatures
Learn how to securely verify webhook signatures to ensure requests are from Exa
When you receive a webhook from Exa, you should verify that it came from us to ensure the integrity and authenticity of the data. Exa signs all webhook payloads with a secret key that's unique to your webhook endpoint.
## How Webhook Signatures Work
Exa uses HMAC SHA256 to sign webhook payloads. The signature is included in the `Exa-Signature` header, which contains:
* A timestamp (`t=`) indicating when the webhook was sent
* One or more signatures (`v1=`) computed using the timestamp and payload
The signature format looks like this:
```
Exa-Signature: t=1234567890,v1=5257a869e7ecebeda32affa62cdca3fa51cad7e77a0e56ff536d0ce8e108d8bd
```
## Verification Process
To verify a webhook signature:
1. Extract the timestamp and signatures from the `Exa-Signature` header
2. Create the signed payload by concatenating the timestamp, a period, and the raw request body
3. Compute the expected signature using HMAC SHA256 with your webhook secret
4. Compare your computed signature with the provided signatures
* **Webset**: Container that organizes your unique collection of web content and its related searches
* **Search**: An agent that searches and crawls the web to find precise entities matching your criteria, adding them to your Webset as structured WebsetItems
* **Item**: A structured result with source content, verification status, and type-specific fields (company, person, research paper, etc.)
* **Enrichment**: An agent that searches the web to enhance existing WebsetItems with additional structured data
## Next Steps
* Follow our [quickstart guide](/websets/api/get-started)
* Learn more about [how it works](/websets/api/how-it-works)
* Browse the [API reference](/websets/api/websets/create-a-webset)
# List webhook attempts
Source: https://docs.exa.ai/websets/api/webhooks/attempts/list-webhook-attempts
get /v0/webhooks/{id}/attempts
List all attempts made by a Webhook ordered in descending order.
# Create a Webhook
Source: https://docs.exa.ai/websets/api/webhooks/create-a-webhook
post /v0/webhooks
# Delete a Webhook
Source: https://docs.exa.ai/websets/api/webhooks/delete-a-webhook
delete /v0/webhooks/{id}
# Get a Webhook
Source: https://docs.exa.ai/websets/api/webhooks/get-a-webhook
get /v0/webhooks/{id}
# List webhooks
Source: https://docs.exa.ai/websets/api/webhooks/list-webhooks
get /v0/webhooks
# Update a Webhook
Source: https://docs.exa.ai/websets/api/webhooks/update-a-webhook
patch /v0/webhooks/{id}
# Verifying Signatures
Source: https://docs.exa.ai/websets/api/webhooks/verifying-signatures
Learn how to securely verify webhook signatures to ensure requests are from Exa
When you receive a webhook from Exa, you should verify that it came from us to ensure the integrity and authenticity of the data. Exa signs all webhook payloads with a secret key that's unique to your webhook endpoint.
## How Webhook Signatures Work
Exa uses HMAC SHA256 to sign webhook payloads. The signature is included in the `Exa-Signature` header, which contains:
* A timestamp (`t=`) indicating when the webhook was sent
* One or more signatures (`v1=`) computed using the timestamp and payload
The signature format looks like this:
```
Exa-Signature: t=1234567890,v1=5257a869e7ecebeda32affa62cdca3fa51cad7e77a0e56ff536d0ce8e108d8bd
```
## Verification Process
To verify a webhook signature:
1. Extract the timestamp and signatures from the `Exa-Signature` header
2. Create the signed payload by concatenating the timestamp, a period, and the raw request body
3. Compute the expected signature using HMAC SHA256 with your webhook secret
4. Compare your computed signature with the provided signatures
## Security Best Practices Following these practices will help ensure your webhook implementation is secure and robust: * **Always Verify Signatures** - Never process webhook data without first verifying the signature. This prevents attackers from sending fake webhooks to your endpoint. * **Use Timing-Safe Comparison** - When comparing signatures, use functions like `hmac.compare_digest()` in Python or `crypto.timingSafeEqual()` in Node.js to prevent timing attacks. * **Check Timestamp Freshness** - Consider rejecting webhooks with timestamps that are too old (e.g., older than 5 minutes) to prevent replay attacks. * **Store Secrets Securely** - Store your webhook secrets in environment variables or a secure secret management system. Never hardcode them in your application. **Important**: The webhook secret is only returned when you [create a webhook](https://docs.exa.ai/websets/api/webhooks/create-a-webhook) - make sure to save it securely as it cannot be retrieved later. * **Use HTTPS** - Always use HTTPS endpoints for your webhooks to ensure the data is encrypted in transit. ***
## Troubleshooting ### Invalid Signature Errors If you're getting signature verification failures: 1. **Check the raw payload**: Make sure you're using the raw request body, not a parsed JSON object 2. **Verify the secret**: Ensure you're using the correct webhook secret from when the webhook was created 3. **Check header parsing**: Make sure you're correctly extracting the timestamp and signatures from the header 4. **Encoding issues**: Ensure consistent UTF-8 encoding throughout the verification process ### Testing Signatures Locally You can test your signature verification logic using the webhook secret and a sample payload: ```python python # Test with a known payload and signature test_payload = '{"type":"webset.created","data":{"id":"ws_test"}}' test_timestamp = "1234567890" test_secret = "your_webhook_secret" # Create test signature import hmac import hashlib signed_payload = f"{test_timestamp}.{test_payload}" test_signature = hmac.new( test_secret.encode('utf-8'), signed_payload.encode('utf-8'), hashlib.sha256 ).hexdigest() test_header = f"t={test_timestamp},v1={test_signature}" # Verify it works is_valid = verify_webhook_signature(test_payload, test_header, test_secret) print(f"Test signature valid: {is_valid}") # Should print True ``` ***
## What's Next? * Learn about [webhook events](/websets/api/events) and their payloads * Set up [webhook retries and monitoring](/websets/api/webhooks/attempts/list-webhook-attempts) * Explore [webhook management endpoints](/websets/api/webhooks/create-a-webhook) # Cancel a running Webset Source: https://docs.exa.ai/websets/api/websets/cancel-a-running-webset post /v0/websets/{id}/cancel Cancels all operations being performed on a Webset. Any enrichment or search will be stopped and the Webset will be marked as `idle`. # Create a Webset Source: https://docs.exa.ai/websets/api/websets/create-a-webset post /v0/websets Creates a new Webset with optional search, import, and enrichment configurations. The Webset will automatically begin processing once created. You can specify an `externalId` to reference the Webset with your own identifiers for easier integration. # Delete a Webset Source: https://docs.exa.ai/websets/api/websets/delete-a-webset delete /v0/websets/{id} Deletes a Webset. Once deleted, the Webset and all its Items will no longer be available. # Cancel a running Enrichment Source: https://docs.exa.ai/websets/api/websets/enrichments/cancel-a-running-enrichment post /v0/websets/{webset}/enrichments/{id}/cancel All running enrichments will be canceled. You can not resume an Enrichment after it has been canceled. # Create an Enrichment Source: https://docs.exa.ai/websets/api/websets/enrichments/create-an-enrichment post /v0/websets/{webset}/enrichments Create an Enrichment for a Webset. # Delete an Enrichment Source: https://docs.exa.ai/websets/api/websets/enrichments/delete-an-enrichment delete /v0/websets/{webset}/enrichments/{id} When deleting an Enrichment, any running enrichments will be canceled and all existing `enrichment_result` generated by this Enrichment will no longer be available. # Get an Enrichment Source: https://docs.exa.ai/websets/api/websets/enrichments/get-an-enrichment get /v0/websets/{webset}/enrichments/{id} # Get a Webset Source: https://docs.exa.ai/websets/api/websets/get-a-webset get /v0/websets/{id} # Delete an Item Source: https://docs.exa.ai/websets/api/websets/items/delete-an-item delete /v0/websets/{webset}/items/{id} Deletes an Item from the Webset. This will cancel any enrichment process for it. # Get an Item Source: https://docs.exa.ai/websets/api/websets/items/get-an-item get /v0/websets/{webset}/items/{id} Returns a Webset Item. # List all Items for a Webset Source: https://docs.exa.ai/websets/api/websets/items/list-all-items-for-a-webset get /v0/websets/{webset}/items Returns a list of Webset Items. You can paginate through the Items using the `cursor` parameter. # List all Websets Source: https://docs.exa.ai/websets/api/websets/list-all-websets get /v0/websets Returns a list of Websets. You can paginate through the results using the `cursor` parameter. # Preview a webset Source: https://docs.exa.ai/websets/api/websets/preview-a-webset post /v0/websets/preview Preview how a search query will be decomposed before creating a webset. This endpoint performs the same query analysis that happens during webset creation, allowing you to see the detected entity type, generated search criteria, and available enrichment columns in advance. Use this to help users understand how their search will be interpreted before committing to a full webset creation. # Cancel a running Search Source: https://docs.exa.ai/websets/api/websets/searches/cancel-a-running-search post /v0/websets/{webset}/searches/{id}/cancel Cancels a currently running Search. You can cancel all searches at once by using the `websets/:webset/cancel` endpoint. # Create a Search Source: https://docs.exa.ai/websets/api/websets/searches/create-a-search post /v0/websets/{webset}/searches Creates a new Search for the Webset. The default behavior is to reuse the previous Search results and evaluate them against the new criteria. # Get a Search Source: https://docs.exa.ai/websets/api/websets/searches/get-a-search get /v0/websets/{webset}/searches/{id} Gets a Search by id # Update a Webset Source: https://docs.exa.ai/websets/api/websets/update-a-webset post /v0/websets/{id} # Exclude Results Source: https://docs.exa.ai/websets/dashboard/exclude-results Avoid duplicate results in your new searches by excluding URLs from previous Websets or CSV files.
## Overview The Exclude Results feature ensures you don't get duplicate results when creating new searches. By specifying URLs to exclude based on previous Websets or uploaded CSV files, you can focus on discovering fresh, unique results that complement your existing data.
## How it works 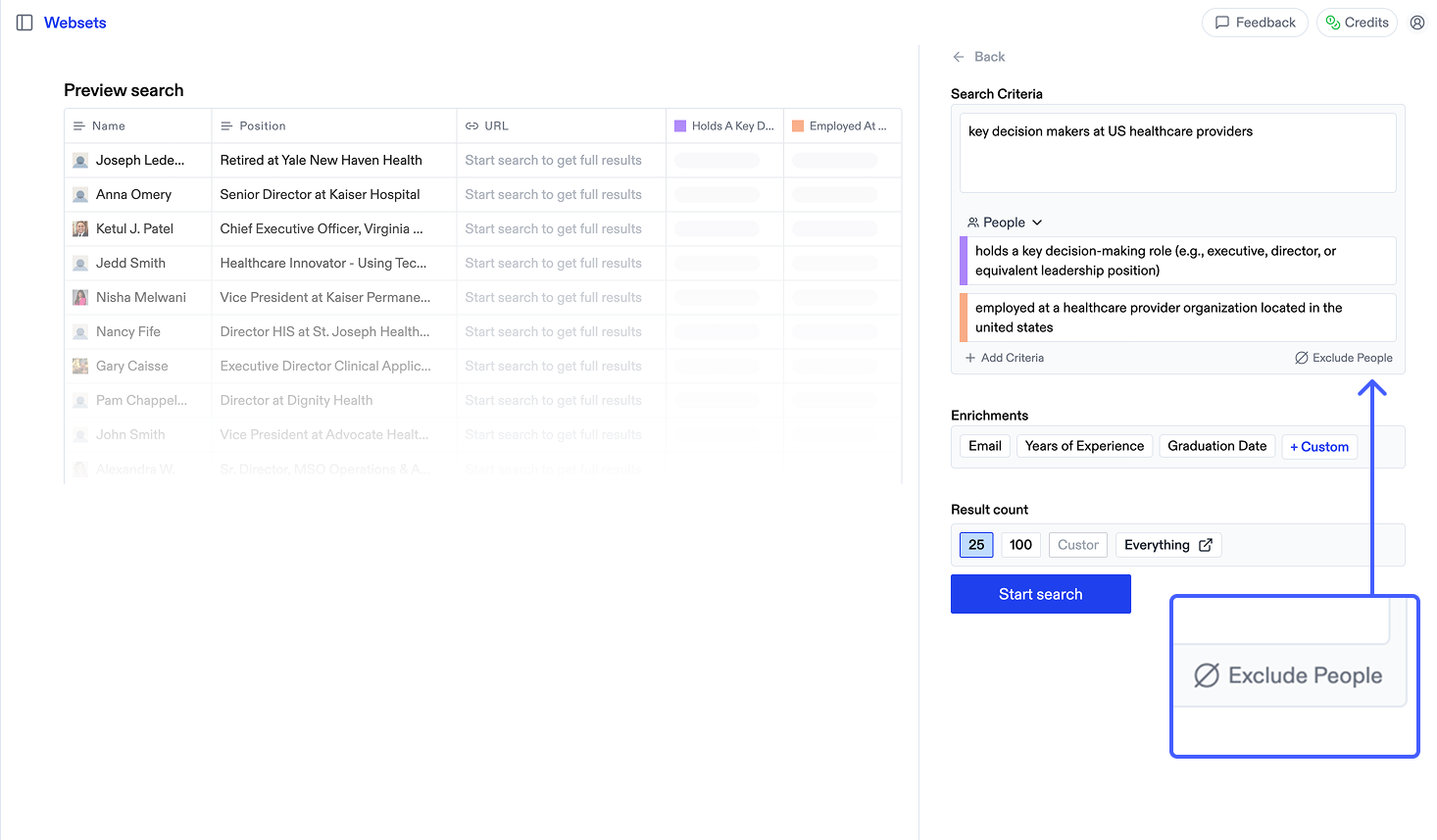 1. Begin creating a new Webset 2. Below the criteria in the sidepanel, click "Exclude" 3. Select from past Websets or upload a CSV with URLs to exclude. You can select multiple sources to exclude from. 4. Start your search, with only new results that don't match your exclusions The maximum number of results you can exclude is determined by your plan.
## When to use exclusions * Finding leads that aren't already in your CRM * Following up on previous searches with refined criteria * Excluding results you already know about # Get started Source: https://docs.exa.ai/websets/dashboard/get-started Welcome to the Websets Dashboard! Find anything you want on the web, no matter how complex.
## 1. Sign up Websets is now generally available at [https://websets.exa.ai/](https://websets.exa.ai/)! If you'd like to ask us about it, [book a call here](https://cal.com/team/exa/websets-enterprise-plan).
## 2. Get started Websets is very easy to use.  1. Describe what you want in plain English - make it as complicated as you'd like!  2. Confirm your criteria and data category look good. 3. Confirm how many results you want, then start your search.
## 3. Inside your Webset In brief, Websets does the following: 1. Break down what you're asking for 2. Find promising data that might satisfy your ask 3. Verify all criteria using AI agents and finding parallel sources 4. Adjust search based on feedback you provide our agent
## 4. Interacting with your Webset Once the Webset is complete, you can interact with the components! Click on a result to see:  1. Its AI-generated summary 2. The criteria it met to be included in the Webset 3. The sources that informed the matching (you can click through the sources here) You can manually delete results, to clean up your Webset before exporting it.
## 5. Add more result criteria and custom columns 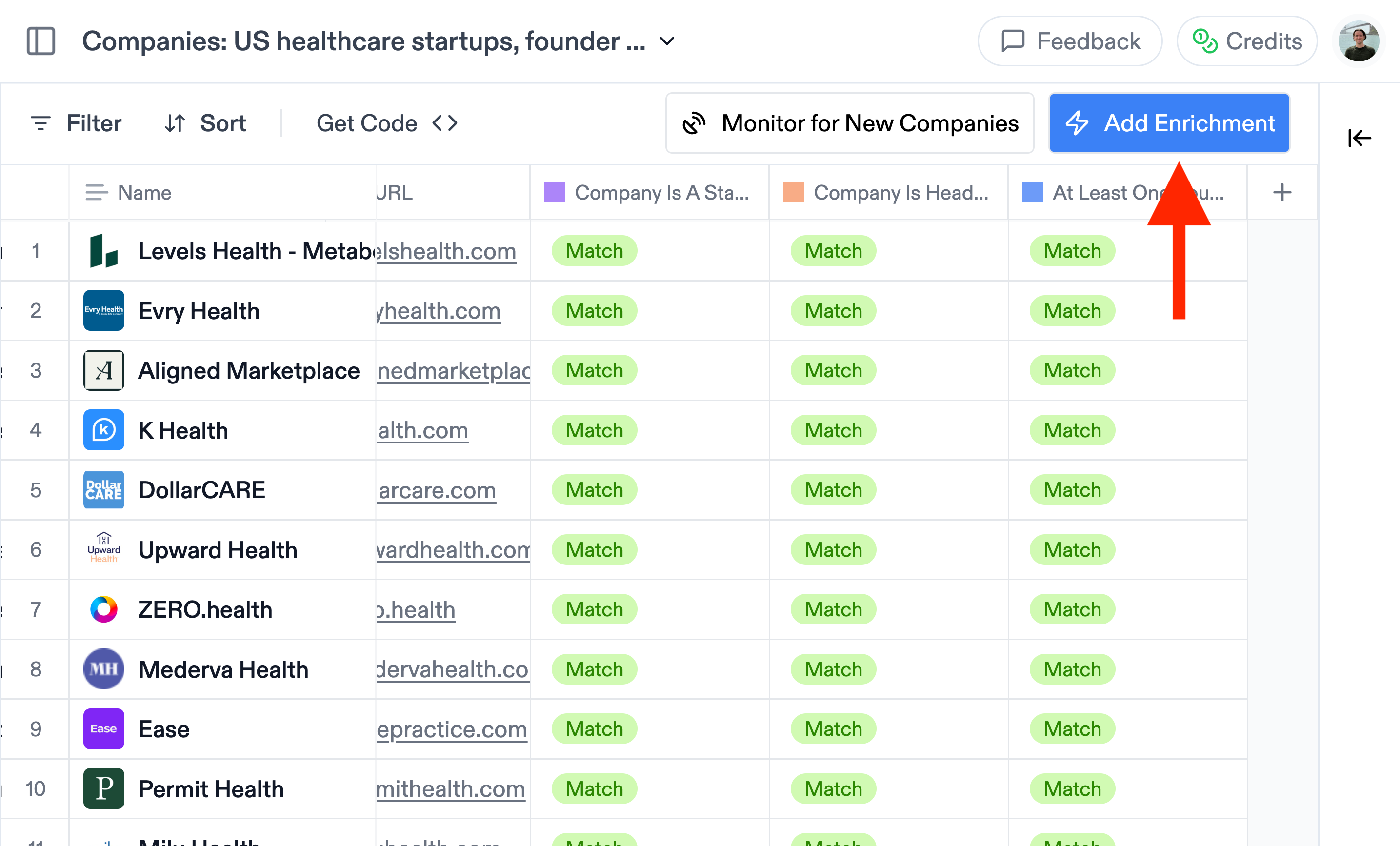 1. **Add enrichments:** You can create custom enrichment columns, asking for any information you want. Think contact information (email & phone number), revenue, employee count, sentiment analysis, summary of the paper, etc. Fill in: * The name of the column (e.g. 'Revenue') * The column type (e.g. 'Number') * Instructions for Websets to find the data (e.g. 'Find the annual revenue of the company') * Or click "fill in for me" for the instructions to be generated automatically by our agent
## 6. Share and export your Webset 1. Click export to download your Webset as a CSV file. 2. Click share to get a link for your Webset.
## 7. Search history If you click on the sidebar icon in the top left, you'll see your full history with all past Websets in the left panel. # Import from CSV Source: https://docs.exa.ai/websets/dashboard/import-from-csv Turn your existing CSV data into a Webset
## Overview The Import from CSV feature allows you to transform your existing CSV files containing URLs into fully-functional Websets. This is perfect when you already have a list of websites, companies, or resources that you want to enrich with additional data or apply search criteria to filter.
## How it works 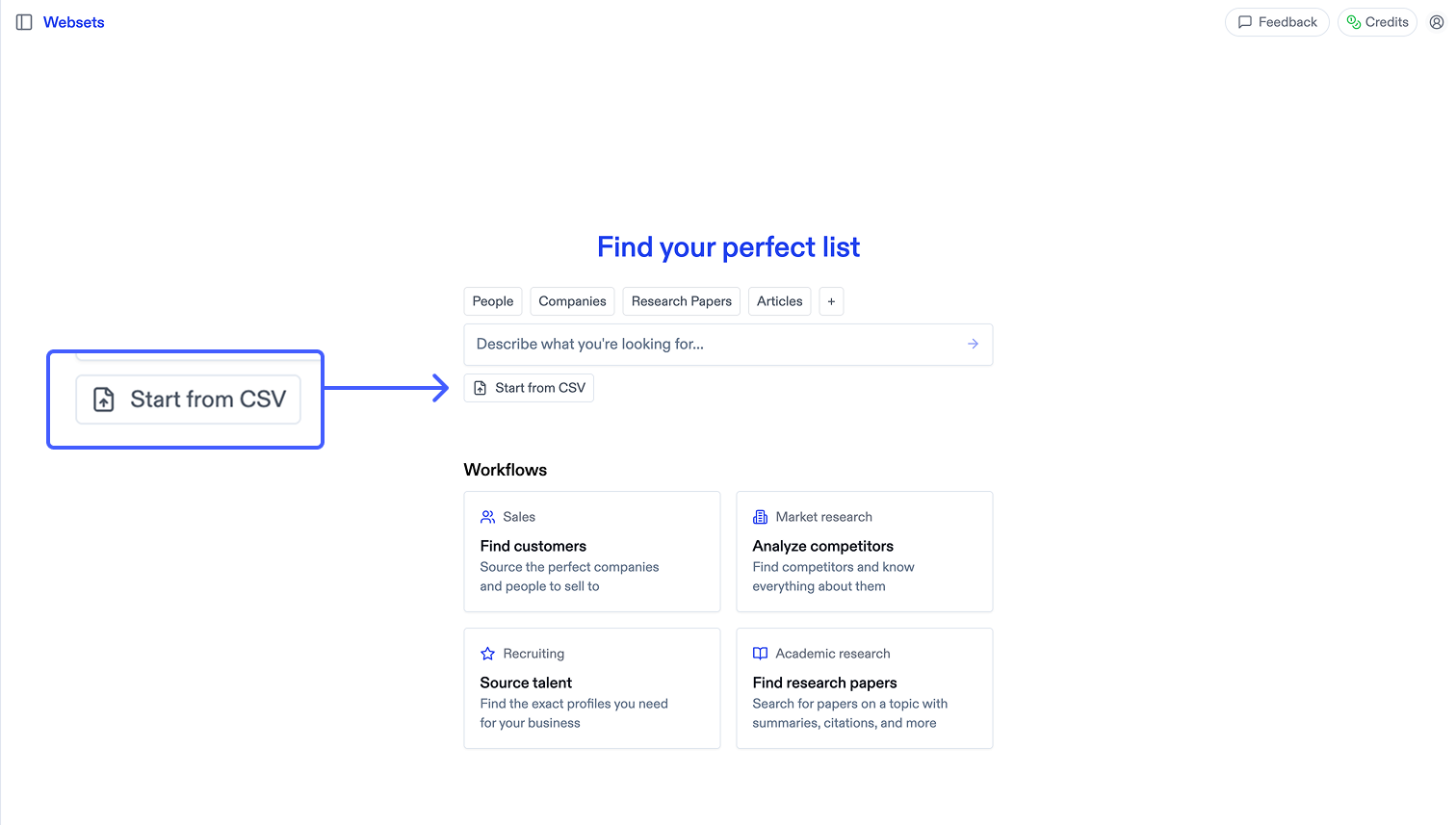 1. Click "Start from CSV" to select your CSV file 2. Select which column contains the URLs you want to analyze 3. Review how your data will be imported before proceeding 4. Your URLs are transformed into a Webset with enrichments and metadata
## CSV preparation Ensure your CSV file has a URL column * For People searches: URLs must be LinkedIn profile URLs (e.g., [https://linkedin.com/in/username](https://linkedin.com/in/username)) * For Company search: URLs must be company homepage URLs (e.g., [https://example.com](https://example.com)) * For other searches: use any type of URL If you do not have URLs, Websets will attempt to infer URLs based on the information in each CSV row and any extra info you provide. The maximum number of results you can import is determined by your plan. ## What happens next? Once imported, your CSV becomes a full Webset where you can: ### Enrich with custom columns Add any information you want about each URL: * Contact information (emails, phone numbers) * Company metrics (revenue, employee count) * Content analysis (sentiment, topics, summaries) * Custom data specific to your use case ### Apply search criteria Filter your imported URLs based on specific criteria: * Company stage or size * Industry or sector * Geographic location * Content type or topic # Integrations Source: https://docs.exa.ai/websets/dashboard/integrations Connect your Websets with popular CRM and email tools
## Overview Websets integrates seamlessly with your favorite CRM, email sequencing, and database tools, allowing you to export enriched data directly where you need it. Manage all your integrations from a single dashboard and keep your workflows streamlined.
## Supported integrations We've built support for leading platforms across sales, marketing, and data enrichment: **CRM Platforms** * [Salesforce](https://www.salesforce.com/) - Export People entities as Leads * [HubSpot](https://www.hubspot.com/) - Export People entities as Contacts **Email Sequencing** * [Instantly](https://instantly.ai/) - Export People entities as Leads * [Smartlead](https://www.smartlead.ai/) - Export People entities as Leads * [Lemlist](https://www.lemlist.com/) - Export People entities as Leads **Data Enrichment** * [Clay](https://www.clay.com/) - Export any entity type via webhook
## Managing integrations 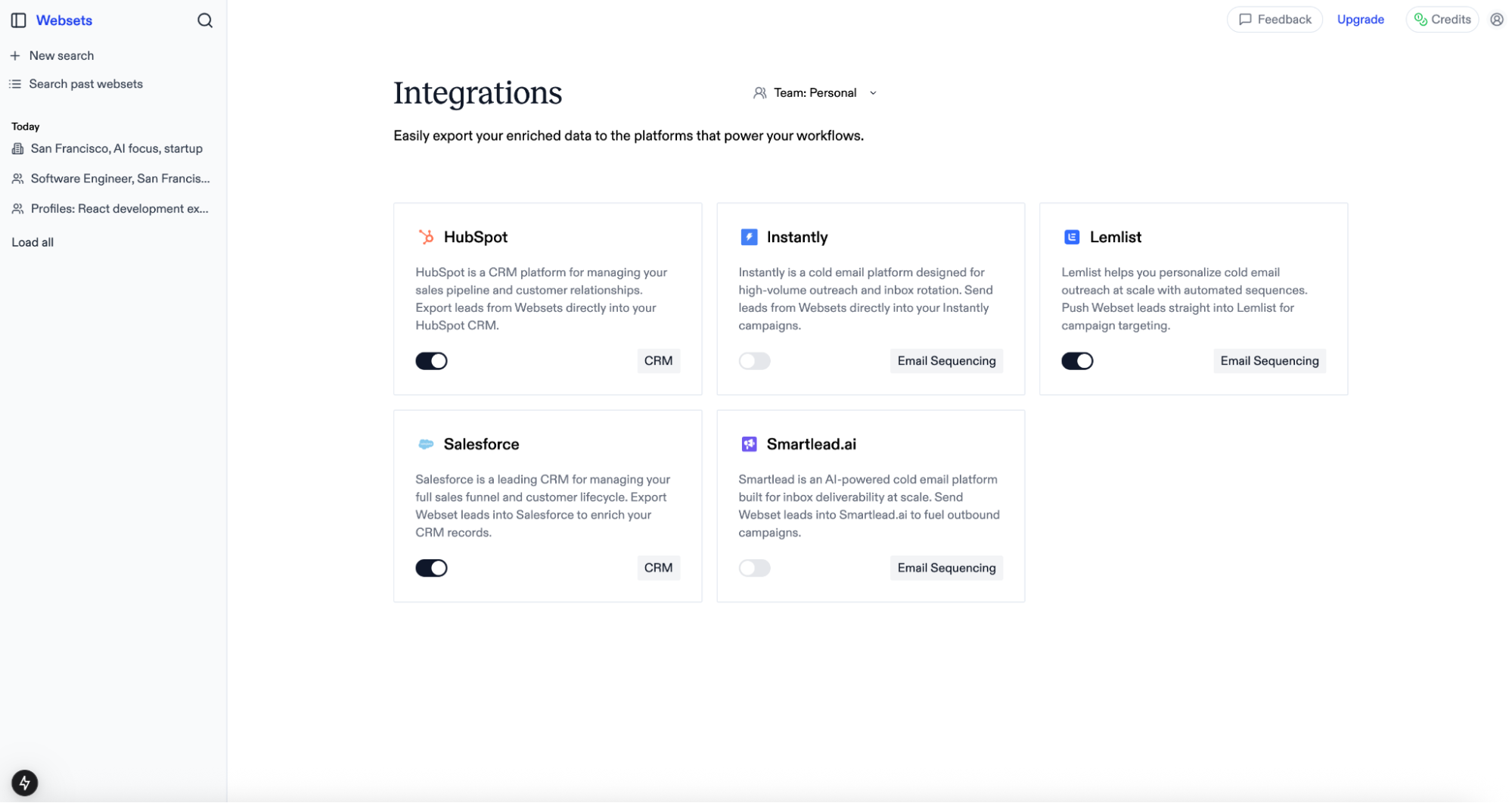 To enable an integration: 1. Visit [https://websets.exa.ai/integrations](https://websets.exa.ai/integrations) 2. Toggle the integration you want to connect 3. Provide your account credentials 4. The integration will be scoped to your currently selected team
## Exporting capabilities Currently, we support **exporting all** your Webset table rows to connected platforms. Import functionality for further enrichment is coming soon. 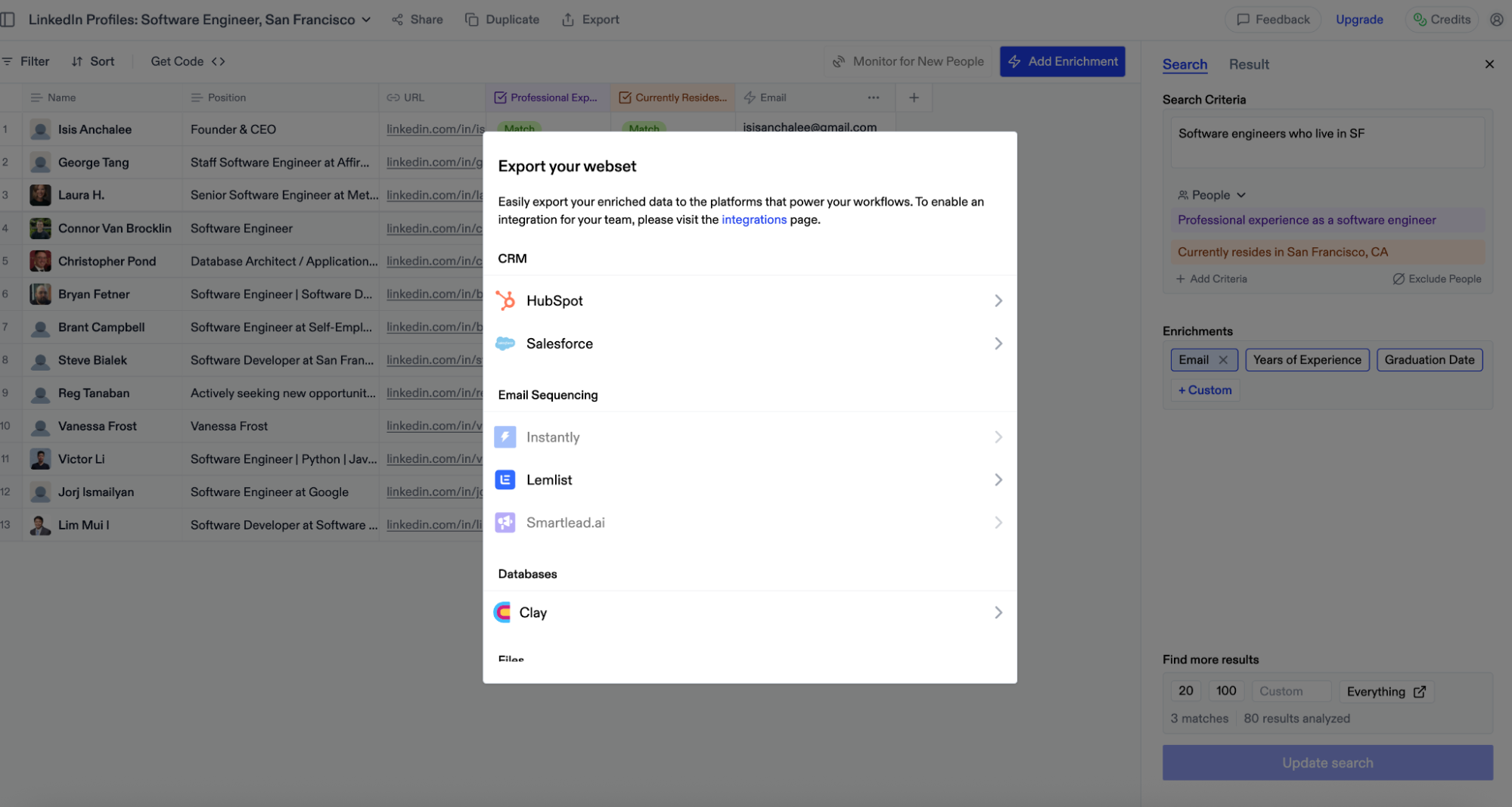
## Setup guides ### Salesforce **Authentication** When you toggle on the Salesforce integration, you'll be redirected to login to your Salesforce account. After logging in, you'll be redirected back and ready to go! **Actions** **Create Leads** – Export any People entity Webset type as **Leads** in your Salesforce account.
### HubSpot **Authentication** When you toggle on the HubSpot integration, you'll be redirected to login to your HubSpot account. You'll be prompted to install the Exa app and grant the requested permissions. After approval, you'll be redirected back and fully connected. **Actions** **Create Contacts** – Export any People entity Webset type as **Contacts** in your HubSpot account.
### Instantly **Authentication** When you toggle on the Instantly integration, you'll need to provide your Instantly API key: 1. Login to your Instantly account and click your avatar in the bottom left corner 2. Select "Settings" from the menu 3. Navigate to the "Integrations" tab 4. Select "API Keys" from the left navigation menu 5. Click "Create API Key" 6. Name your key and select "all:all" for scopes 7. Copy and paste the generated key into Websets **Actions** **Create Leads** – Export any People entity Webset type as **Leads** in your Instantly account.
### Smartlead **Authentication** When you toggle on the Smartlead integration, you'll need to provide your Smartlead API key: 1. Login to your Smartlead account and click your avatar in the top right corner 2. Select "Settings" from the menu 3. Scroll down to "Smartlead API Key" 4. Copy your existing key or generate a new one 5. Paste the key into Websets and click connect **Actions** **Create Leads** – Export any People entity Webset type as **Leads** in your Smartlead account.
### Lemlist **Authentication** When you toggle on the Lemlist integration, you'll need to provide your Lemlist API key: 1. Login to your Lemlist account and click your name in the bottom left corner 2. Select "Settings" from the menu 3. Click "Integrations" in the left menu 4. Find the "API overview" section and click "Generate" 5. Name your key and click "Create Key" 6. Copy and paste the generated key into Websets **Actions** **Create Leads** – Export any People entity Webset type as **Leads** in your Lemlist account.
### Clay **Authentication** No authentication is required for Clay integration, as we currently support exporting Webset data via webhook only. **Note: A Clay Pro account is required.** **Creating a webhook** 1. Navigate to a Clay table and click "Add" at the bottom 2. Search for "Webhook" and select it 3. This creates a new table view with a Webhook column 4. Copy the webhook URL from the "Pull in data from a Webhook" panel on the right **Actions** **Create table rows** – Export Websets of any entity type to Clay: 1. From a Webset, click "Export" in the top navigation 2. Select the "Clay" integration option 3. Paste the webhook URL from Clay 4. Click "Export" Your Webset rows will populate your Clay table within moments. 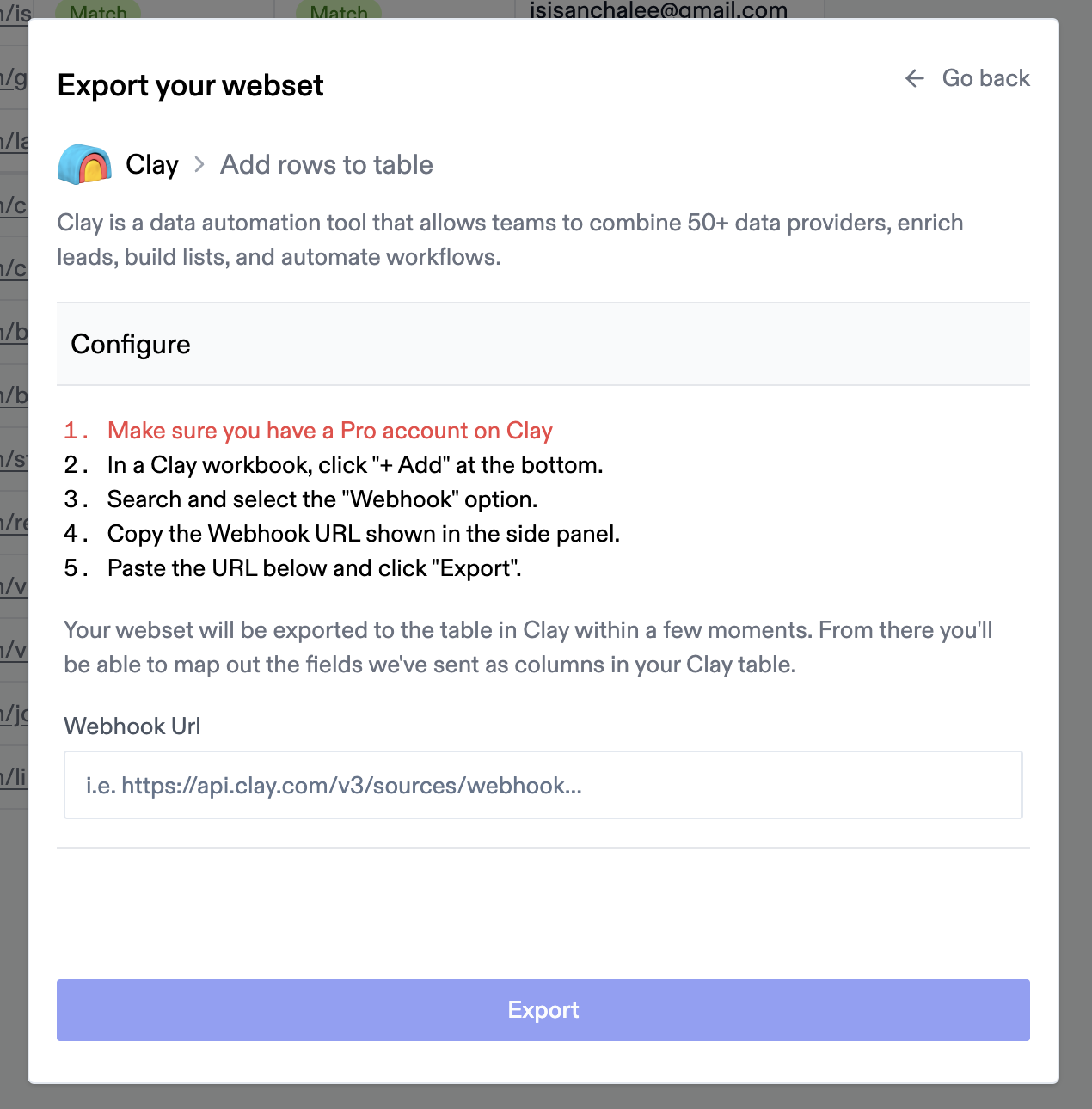 # Creating Enrichments Source: https://docs.exa.ai/websets/dashboard/walkthroughs/Creating-enrichments Here's how to create enrichments (also known as Adding Columns). **Open the enrichment modal**
## Recruiting 1. Engineers with startup experience, that have contributed to open source projects 2. Candidate with strong analytical and operational skills, that has worked at a startup before 3. SDR, with experience selling healthcare products, based in the East Coast 4. ML Software engineers or computer science PhD students that went to a top 20 US university. 5. Investment banker or consultant, attended an Ivy League, has been at their role for over 2 years.
## Market Research/Investing 1. Linkedin profile of person that has changed their title to “Stealth Founder” in 2025 2. Companies in the agrotech space focused on hardware solutions 3. Financial reports of food & beverage companies that mention team downsizing 4. Fintech startups that raised a series A in 2024 from a major US based VC fund
## Sourcing 1. Hydrochlorous acid manufacturers that have sustainability angles 2. High end clothing, low minimum order quantity manufacturers in Asia or Europe 3. Software solutions for fleet management automation 4. Cool agentic AI tools to help with productivity
## Research Papers 1. Research papers, published in a major US journal, focused on cell generation technology 2. Research papers that disagree with transformer based model methodology for AI training 3. Research papers written by someone with a phd, focused on astrophysics. # FAQ Source: https://docs.exa.ai/websets/faq Frequently asked questions about Websets ***
## Get Started You can use Websets in two ways: 1. Through our intuitive Dashboard interface - perfect for quickly finding what you need without any coding 2. Via our powerful API - ideal for programmatic access and integration into your workflow
Use Websets through our Dashboard.
Use Websets programatically through our API.