What this doc covers
- Brief intro to LangGraph
- How to set up an agent in LangGraph with Exa search as a tool
Guide
This guide will show you how you can define and use Exa search within the LangGraph framework. This framework provides a straightforward way for you to define an AI agent and for it to retrieve high-quality, semantically matched content via Exa search.Brief Intro to LangGraph
Before we dive into our implementation, a quick primer on the LangGraph framework. LangGraph is a powerful tool for building complex LLM-based agents. It allows for cyclical workflows, gives you granular control, and offers built-in persistence. This means you can create reliable agents with intricate logic, pause and resume execution, and even incorporate human oversight. Read more about LangGraph hereOur Research Assistant Workflow
For our AI-powered research assistant, we’re leveraging LangGraph’s capabilities to create a workflow that combines an AI model (Claude) with a web search retrieval tool powered by Exa’s API, to fetch, find and analyze any documents (in this case research on climate tech). Here’s a visual representation of our workflow: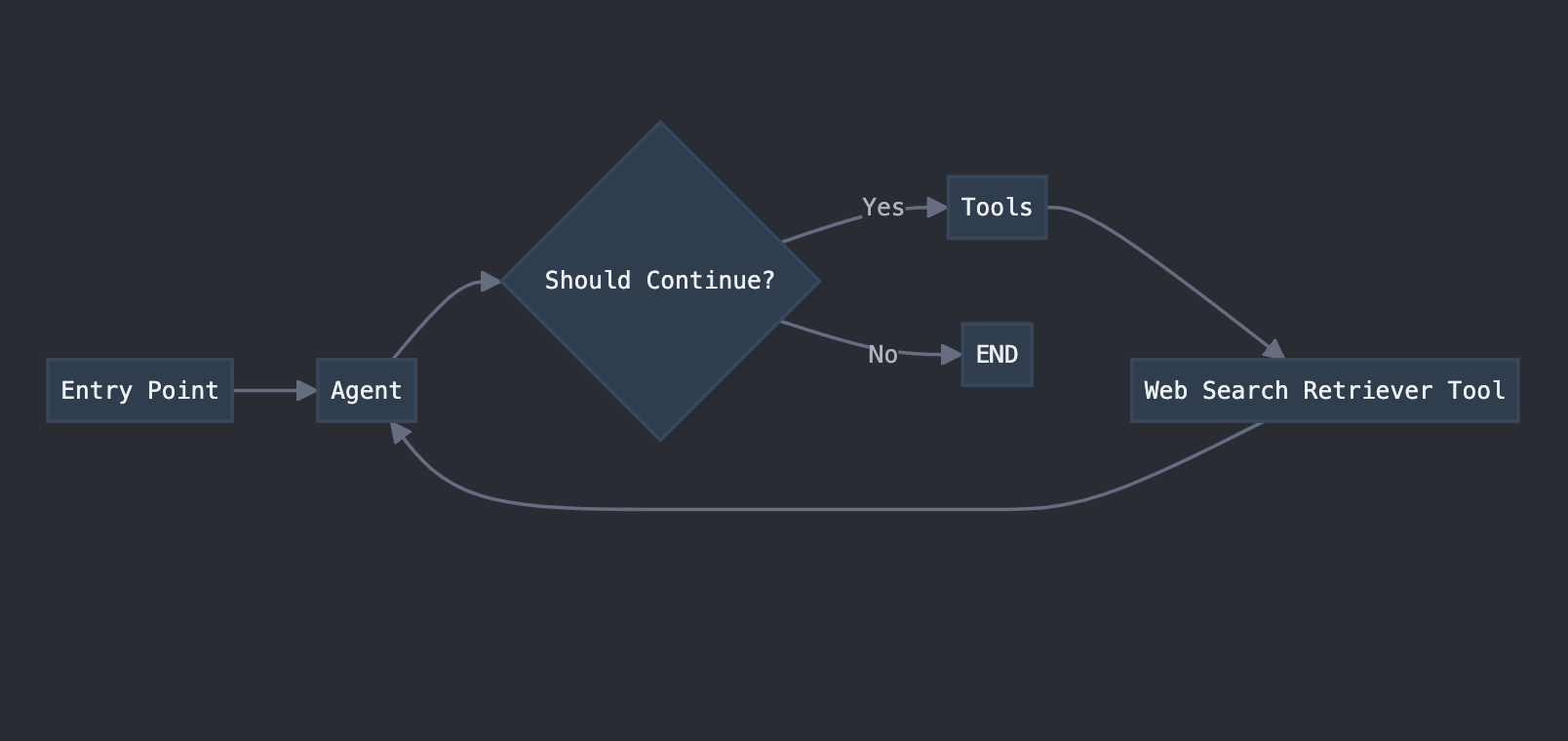 This diagram illustrates how our workflow takes advantage of LangGraph’s cycle support, allowing the agent to repeatedly use tools and make decisions until it has gathered sufficient information to provide a final response.
This diagram illustrates how our workflow takes advantage of LangGraph’s cycle support, allowing the agent to repeatedly use tools and make decisions until it has gathered sufficient information to provide a final response.
Let’s break down what’s happening in this simple workflow:
- We start at the Entry Point with a user query (e.g., “Latest research papers on climate technology”).
- The Agent (our AI model) receives the query and decides what to do next.
- If the Agent needs more information, it uses the Web Search Retriever Tool to search for relevant documents.
- The Web Search Retriever Tool fetches information using Exa’s semantic search capabilities.
- The Agent receives the fetched information and analyzes it.
- This process repeats until the Agent has enough information to provide a final response.
1. Prerequisites and Installation
Before starting, ensure you have the required packages installed:ANTHROPIC_API_KEY and EXA_API_KEY for Anthropic and Exa keys respectively.
Get your Exa API key
2. Set Up Exa Search as a LangChain Tool
After setting env variables, we can start configuring a search tool usingExaSearchRetriever. This tool (read more here) will help retrieve relevant documents based on a query.
First we need to import the required libraries:
tool decorator which you can read more about here. The decorator uses the function name as the tool name. The docstring provides the agent with a tool description.
The retriever is where we initialize the Exa search retriever and configure it with parameters such as highlights=True. You can read more about all the available parameters here.
ExaSearchRetriever is set to fetch 3 documents.
Then we use LangChain’s PromptTemplate to structure the results from Exa in a more AI friendly way. Creating and using this template is optional, but recommended. Read more about PromptTemplate (here.
We also use a RunnableLambda to extract necessary metadata (like URL and highlights) from the search results and format it using the prompt template.
After all of this we start the retrieval and processing chain and store the results in the documents variable which is returned.
3. Creating a Toolchain with LangGraph
Now let’s set up the complete toolchain using LangGraph.Define Workflow Functions
Create functions to manage the workflow:Build the Workflow Graph
4. Running Your Workflow
We are approaching the finish line of our Exa-powered search agent.Invoke and run
Text output